疯狂下载小视频
0x01 分析网站视频
我接触的小视频网站分类两类
A: 播放器对视频进行加密过的
B:直接mp4的播放(这一类其实很多很多)
对A类视频探测下载地址的方式:
直接使用浏览器自带的插件, 找到network选项 使用常用的 视频格式进行过滤, 如下图所示的分析方式
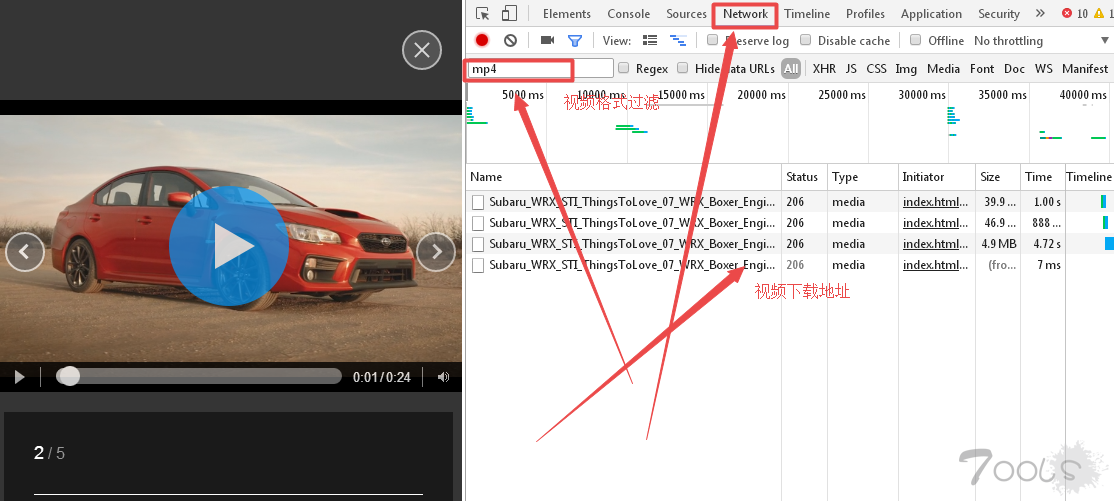
直接可以探测到 下载地址
备注: 有时候经常会探测到 .ts的文件, ckplayer的播放器经常会遇到这种格式, 不要惊慌, 全部下载下来, 然后用格式工厂的工具,进行视频文件组合即可。
对B类的视频文件就简单了:
右键直接点击下载视频, 这个不讲解
0x02 批量下载
有时候太猥琐, 想把网站的视频全部下载下来。
给大家我用的思路与方法吧
拿到视频的下载地址以后
地址分为几类:
www.xxx.com/video/aa001.mp4
www.xxx.com/video/aa002.mp4
www.xxx.com/video/aa00*.mp4
这类的视频下载地址, 直接进行可以下载了,工具【迅雷】
两种方式
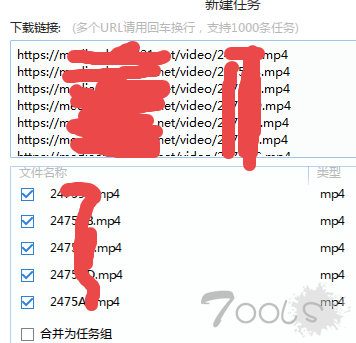
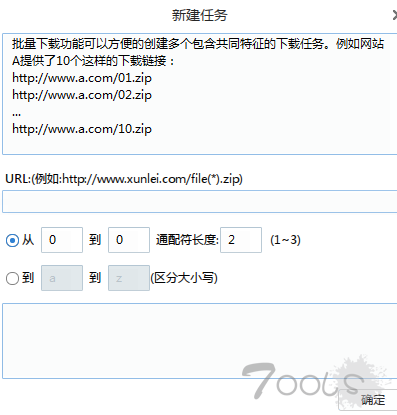
迅雷提供的另种批量下载的方式: 链接批量下载, 还有一种正则表达式的方式!
对于这类 没有对url进行加密的 ,批量扒下来。
类似这样:
www.xxx.com/video/9452ab54287bbccc989.mp4
一段没有任何规律的字符, 可以适当分析一下他的加密方式, 分析不出来就放弃吧。
对于这类的网站,给大家一个思路:
a:首先写一个爬虫脚本, 爬取所有播放页面的URL
b:写一个脚本,对每个页面的播放地址进行分析
这种思路, 基本可以解决所有的问题了。
0x03 效果展示
说明: 很简单的一种扒视频的方法, 只是给大家分享一下自己的思路,没啥技术含量。
TCV : 0
我接触的小视频网站分类两类
A: 播放器对视频进行加密过的
B:直接mp4的播放(这一类其实很多很多)
对A类视频探测下载地址的方式:
直接使用浏览器自带的插件, 找到network选项 使用常用的 视频格式进行过滤, 如下图所示的分析方式
直接可以探测到 下载地址
备注: 有时候经常会探测到 .ts的文件, ckplayer的播放器经常会遇到这种格式, 不要惊慌, 全部下载下来, 然后用格式工厂的工具,进行视频文件组合即可。
对B类的视频文件就简单了:
右键直接点击下载视频, 这个不讲解
0x02 批量下载
有时候太猥琐, 想把网站的视频全部下载下来。
给大家我用的思路与方法吧
拿到视频的下载地址以后
地址分为几类:
www.xxx.com/video/aa001.mp4
www.xxx.com/video/aa002.mp4
www.xxx.com/video/aa00*.mp4
这类的视频下载地址, 直接进行可以下载了,工具【迅雷】
两种方式
迅雷提供的另种批量下载的方式: 链接批量下载, 还有一种正则表达式的方式!
对于这类 没有对url进行加密的 ,批量扒下来。
类似这样:
www.xxx.com/video/9452ab54287bbccc989.mp4
一段没有任何规律的字符, 可以适当分析一下他的加密方式, 分析不出来就放弃吧。
对于这类的网站,给大家一个思路:
a:首先写一个爬虫脚本, 爬取所有播放页面的URL
b:写一个脚本,对每个页面的播放地址进行分析
这种思路, 基本可以解决所有的问题了。
0x03 效果展示
说明: 很简单的一种扒视频的方法, 只是给大家分享一下自己的思路,没啥技术含量。
TCV : 0
评论62次
QQ浏览器有一个叫 猫抓 的插件,推荐,
好有含量的一个文章呀 tOOLS
分段的ts文件能用python也整一个工具出来吗?
分段的 如果名称有规律可以采集, 如果名称也是加密过的, 没有想到好的处理思路
分段的ts文件能用python也整一个工具出来吗?
火狐有个插件 视频地址探测的貌似也很方便
现在好多视频都是分段的,一个视频分成好多个小视频
m3u8了解一下
看看,来学xi
各类视频严打 保留自己看么?
IDM自己检测视频地址,省的看源码抓包,还可以批量下载,速度杠杠滴
遇到过名字是加密的
好思路~~这就去找找看
记得以前有专门找视频地址的软件,不过还是自己找地址最靠谱
还用这样费事吗?> f12 抓虾包 分分钟搞定!
又把我骗进来了
老司机好多的, 看看吧。
又把我骗进来了
有些视频格式是.ts等需要合并
硕鼠,你值得拥有
学xi了!!!!!
迅雷有个功能 下载当前页面全部链接