疯狂下载小视频
0x01 分析网站视频
我接触的小视频网站分类两类
A: 播放器对视频进行加密过的
B:直接mp4的播放(这一类其实很多很多)
对A类视频探测下载地址的方式:
直接使用浏览器自带的插件, 找到network选项 使用常用的 视频格式进行过滤, 如下图所示的分析方式
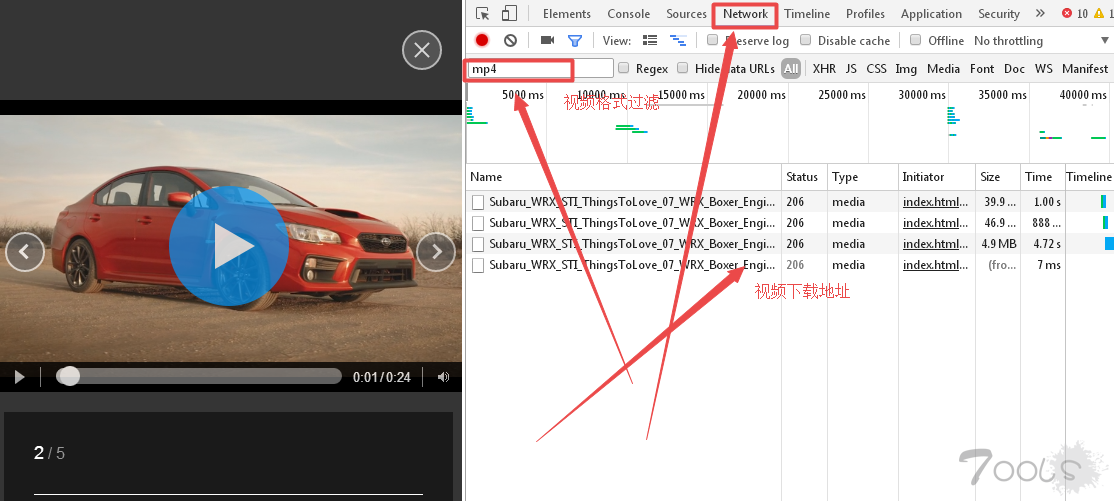
直接可以探测到 下载地址
备注: 有时候经常会探测到 .ts的文件, ckplayer的播放器经常会遇到这种格式, 不要惊慌, 全部下载下来, 然后用格式工厂的工具,进行视频文件组合即可。
对B类的视频文件就简单了:
右键直接点击下载视频, 这个不讲解
0x02 批量下载
有时候太猥琐, 想把网站的视频全部下载下来。
给大家我用的思路与方法吧
拿到视频的下载地址以后
地址分为几类:
www.xxx.com/video/aa001.mp4
www.xxx.com/video/aa002.mp4
www.xxx.com/video/aa00*.mp4
这类的视频下载地址, 直接进行可以下载了,工具【迅雷】
两种方式
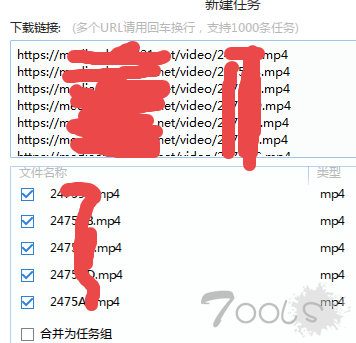
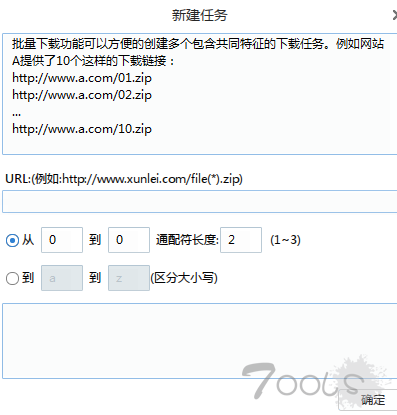
迅雷提供的另种批量下载的方式: 链接批量下载, 还有一种正则表达式的方式!
对于这类 没有对url进行加密的 ,批量扒下来。
类似这样:
www.xxx.com/video/9452ab54287bbccc989.mp4
一段没有任何规律的字符, 可以适当分析一下他的加密方式, 分析不出来就放弃吧。
对于这类的网站,给大家一个思路:
a:首先写一个爬虫脚本, 爬取所有播放页面的URL
b:写一个脚本,对每个页面的播放地址进行分析
这种思路, 基本可以解决所有的问题了。
0x03 效果展示
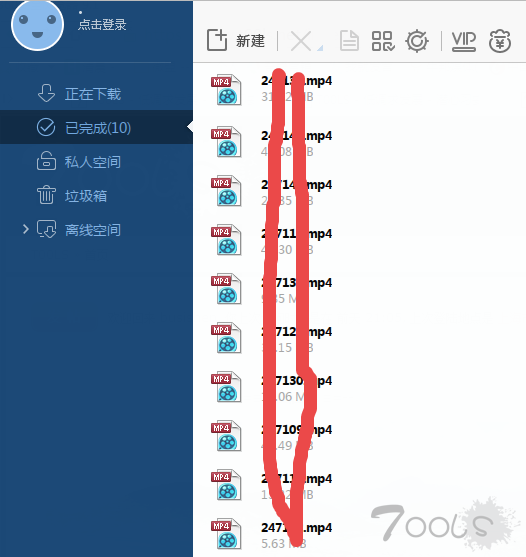
说明: 很简单的一种扒视频的方法, 只是给大家分享一下自己的思路,没啥技术含量。
TCV : 0
我接触的小视频网站分类两类
A: 播放器对视频进行加密过的
B:直接mp4的播放(这一类其实很多很多)
对A类视频探测下载地址的方式:
直接使用浏览器自带的插件, 找到network选项 使用常用的 视频格式进行过滤, 如下图所示的分析方式
直接可以探测到 下载地址
备注: 有时候经常会探测到 .ts的文件, ckplayer的播放器经常会遇到这种格式, 不要惊慌, 全部下载下来, 然后用格式工厂的工具,进行视频文件组合即可。
对B类的视频文件就简单了:
右键直接点击下载视频, 这个不讲解
0x02 批量下载
有时候太猥琐, 想把网站的视频全部下载下来。
给大家我用的思路与方法吧
拿到视频的下载地址以后
地址分为几类:
www.xxx.com/video/aa001.mp4
www.xxx.com/video/aa002.mp4
www.xxx.com/video/aa00*.mp4
这类的视频下载地址, 直接进行可以下载了,工具【迅雷】
两种方式
迅雷提供的另种批量下载的方式: 链接批量下载, 还有一种正则表达式的方式!
对于这类 没有对url进行加密的 ,批量扒下来。
类似这样:
www.xxx.com/video/9452ab54287bbccc989.mp4
一段没有任何规律的字符, 可以适当分析一下他的加密方式, 分析不出来就放弃吧。
对于这类的网站,给大家一个思路:
a:首先写一个爬虫脚本, 爬取所有播放页面的URL
b:写一个脚本,对每个页面的播放地址进行分析
这种思路, 基本可以解决所有的问题了。
0x03 效果展示
说明: 很简单的一种扒视频的方法, 只是给大家分享一下自己的思路,没啥技术含量。
TCV : 0
评论62次
分分段视频,有没什么方法合并到一块
看后缀咯 如果是mp4 就cmd里面 copy /b *.mp4 mix.mp4
.ts的小的文件合并,这个点get到了。
百度 同名字的视频 找个是mp4的下载。
正好今天在测试优酷视频的时候发现,很多视频抓取下来的都是.ts的文件,原来可以直接用格式工厂搞... 还有Y2B的方便,抓取地址后可以直接在线转了之后再下载
用过了,还是感谢,另外#2和#10是个什么意思,发了也不说下,里面还有固定编码,还是下载图片,毛用?!
分分段视频,有没什么方法合并到一块
可以下点小视频游览一二,这个有点像去撸91的爆破方法
嘿嘿 可以可以 学xi到知识了。那拖那些网上收费的水平嘞。嘿嘿。
#!/usr/bin/env python# -*- conding:utf-8 -*- import urllib.requestimport re,os,socket,base64url = base64.b64decode('aHR0cHM6Ly8yMDE3MTJtcDQuODlzb3NvLmNvbS8=').decode('utf-8')jpgs = urllist = def jpg(url,j): '''下载图片''' if os.path.exists('jpg') == False: os.mkdir('jpg') os.mkdir('jpg\\%s'%(j)) for y in range(1, 24): count = 1 os.mkdir('jpg\\%s\\%s' %(j,y)) for z in jpgs: try: k =url+"/"+str(y)+"/"+z #print(k) xmlurl = url+"/"+str(y)+"/"+"1/xml/index.xml" if count == 10: data = urllib.request.urlopen(xmlurl).read().decode() redata = re.compile(r'http.*?\.mp4') datas = redata.findall(data) counts = 1 for i in datas: with open("jpg\\%s\\%s\\mp4_%s.html" % (j, y,counts), 'a') as f: f.write('<video src="%s" controls="controls"'%(i)) f.write(r" width='100%' height='100%'></video>") counts +=1 print("视频以保存到目录下的html文件中") socket.setdefaulttimeout(5) #下载5秒没反应 就跳过 urllib.request.urlretrieve(k,"jpg\\%s\\%s\\%s.jpg"%(j,y,count)) print("正在下载第%s组第%s张照片"%(y,count)) count += 1 except urllib.error.HTTPError as e: print(e,"下载第%s组第%s张照片失败,下载还在继续!"%(y,count)) count += 1 except urllib.error.URLError as e: print(e,"下载第%s组第%s张照片失败,下载还在继续!"%(y,count)) count += 1 except socket.timeout as e: print(e,"下载第%s组第%s张照片失败,下载还在继续!"%(y,count)) count +=1for i in urllist: j = url + i jpg(j,i)
base编码蛮有意思的,哈哈。 下次倒是可以试试time模块。最起码代码不显的那么长~~~
师傅的思路很猥琐呀。。又学会了新车技。。
360上也有自带的工具,和这个思路应该差不多
url列目录漏洞。。直接wget -m不就好了
这个不错,刚好最近寂寞空虚冷,想下点小视频,哈哈
土司可以开个爬虫专题了。
你们都是老司机,硬盘里已经不缺这些东西了
火狐浏览器很早就有这总专门的插件了。 https://jingyan.baidu.com/article/20095761d6e467cb0721b400.html
#!/usr/bin/env python# -*- conding:utf-8 -*- import urllib.requestimport re,os,socket,base64url = base64.b64decode('aHR0cHM6Ly8yMDE3MTJtcDQuODlzb3NvLmNvbS8=').decode('utf-8')jpgs = urllist = def jpg(url,j): '''下载图片''' if os.path.exists('jpg') == False: os.mkdir('jpg') os.mkdir('jpg\\%s'%(j)) for y in range(1, 24): count = 1 os.mkdir('jpg\\%s\\%s' %(j,y)) for z in jpgs: try: k =url+"/"+str(y)+"/"+z #print(k) xmlurl = url+"/"+str(y)+"/"+"1/xml/index.xml" if count == 10: data = urllib.request.urlopen(xmlurl).read().decode() redata = re.compile(r'http.*?\.mp4') datas = redata.findall(data) counts = 1 for i in datas: with open("jpg\\%s\\%s\\mp4_%s.html" % (j, y,counts), 'a') as f: f.write('<video src="%s" controls="controls"'%(i)) f.write(r" width='100%' height='100%'></video>") counts +=1 print("视频以保存到目录下的html文件中") socket.setdefaulttimeout(5) #下载5秒没反应 就跳过 urllib.request.urlretrieve(k,"jpg\\%s\\%s\\%s.jpg"%(j,y,count)) print("正在下载第%s组第%s张照片"%(y,count)) count += 1 except urllib.error.HTTPError as e: print(e,"下载第%s组第%s张照片失败,下载还在继续!"%(y,count)) count += 1 except urllib.error.URLError as e: print(e,"下载第%s组第%s张照片失败,下载还在继续!"%(y,count)) count += 1 except socket.timeout as e: print(e,"下载第%s组第%s张照片失败,下载还在继续!"%(y,count)) count +=1for i in urllist: j = url + i jpg(j,i)
这段是认真的吗?是不想让人看网址?
.ts格式,原来还可以用格式工厂的工具,进行视频文件组合。 第一次知道,学xi了
又一波小视频下载
ffmpeg可以合并.m3u8文件